
http://www.computerworld.es/tendencias/microsoft-tiene-grandes-planes-para-net-core
Como comentamos habitualmente los que somos ya "viejunos" en tecnología.. hay que tener cuidado con las modas, sobre todo cuando tienes entre manos proyectos en producción y no te dedicas sólo a hacer pruebas de conceptos, hackathons o similares.
Hay que distinguir entre los planes de Microsoft, los de tu empresa y los tuyos personales y adoptar una estrategia en consecuencia.
Merece la pena echar un vistazo a los posts relativos a la adopción de tecnología que se vienen publicando en el blog de Tom Graves.
Concretamente, en uno de los más recientes se comenta sobre la perspectiva temporal a tener en cuenta en el ciclo de vida de adopción de nuevas tecnologías:
http://weblog.tetradian.com/2016/08/14/technology-adoption-and-time-horizons/
Ante todo, cabe situarte a ti o a ti empresa en una posición con respecto a la tecnología en estudio:
- ‘Visionaries’ : Innovators : Pioneers
- ‘Shapers’ : Early Adopters : Settlers
- ‘Adaptors’ : Early Majority : Town-Planners
- ‘Classical’ : Late Majority : Exploiters
Las estadísticas son siempre orientativas ya que no hay dos empresas iguales, pero, dan un orden de magnitud. Si categorizas el esfuerzo tecnológico de esta manera:
- Horizon 1: Extend; Current products; Short-term; 0-18 months
- Horizon 2: Build; Next-generation products; Medium-term; 12-36 months
- Horizon 3: Create; Emerging products; Long-term; 24-72 months
puedes crearte un marco temporal:
- Lo que puedo hacer en el plazo de un año extendiendo los productos/tecnologías actuales
- Lo que supone un cambio a nivel de plataforma (por ejemplo, vamos a migrar todos nuestros productos y desarrollos VS2010 a 2015)
- Lo que supone adoptar productos, tecnologías y mercados totalmente nuevos (por ejemplo, queremos desarrollar productos para el segmento IoT
En función de dicho posicionamiento, es más factible planificar la adopción de la tecnología de la forma más racional y eficiente posible, asegurando la continuidad y calidad del servicio sin acumular deuda tecnológica en el que la tecnología acaba suponiendo un lastre para el negocio.
Por tanto, volviendo a lo de NET Core, lo recomendable sería, primero conocerlo, después ver las ventajas que te pueden aportar y finalmente planificar su adopción paulatina en los escenarios que aplique.
Como indican también en Tetradian, el gap entre el laboratorio y producción puede ser frustrante y costoso.
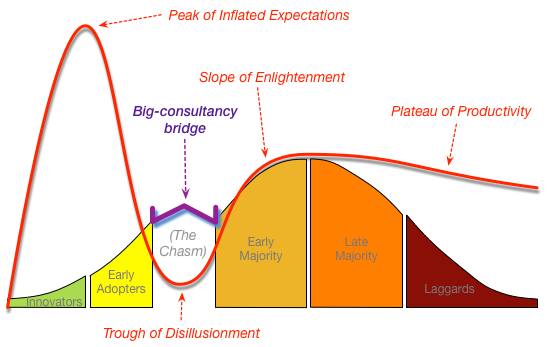
Normalmente, para esa discontinuidad lo apropiado es contratar consultoría especializada, aunque los consultores no pueden suplir tu parte del trabajo, porque a fin de cuentas, no conocen tu negocio, ni tus sistemas, metodologías o restricciones.
Puedes buscar colaboradores o conocimiento experto pero es tu responsabilidad definir el proyecto y liderarlo.
Microsoft lo hace..









.jpg)



 Por tanto, la información puede que sean los ladrillos.. pero, hace falta el cemento.. y.. muchas más cosas.. por ejemplo, saber qué quieres construir.
Por tanto, la información puede que sean los ladrillos.. pero, hace falta el cemento.. y.. muchas más cosas.. por ejemplo, saber qué quieres construir. "¿QUIERES MOVER EL CULOOO O QUE? ¡¡¡QUE LLEVAS UNA HORA Y NO HAS PUESTO NI DOS LADRILLOS!!"
"¿QUIERES MOVER EL CULOOO O QUE? ¡¡¡QUE LLEVAS UNA HORA Y NO HAS PUESTO NI DOS LADRILLOS!!"

